Abstract Art Images Non Commercial Abstract City Art Images Non Commercial
Creating Abstract Art with StyleGAN2 ADA
How I used Adaptive Discriminator Augmentation and Learning Transfer to generate improved abstract paintings with AI.

Back in August 2020, I created a project called MachineRay that uses Nvidia'due south StyleGAN2 to create new abstract artwork based on early 20th century paintings that are in the public domain. Since then, Nvidia has released a new version of their AI model, StyleGAN2 ADA, that is designed to yield better results when generating images from a limited dataset [1]. (I'm not sure why they didn't call it StyleGAN3, but I'll refer to the new model as SG2A to salvage a few characters). In this article, I'll evidence you how I used SG2A to create better looking abstract paintings.
MachineRay ii
Overview
Similar to the original Auto Ray, I am using abstract paintings that are in the public domain every bit my source images to train the SG2A system. I and so change the aspect ratio as part of the mail service-processing. This diagram shows the menstruum through the system.

Everything starts with the 850 images I scraped from WikiArt.org using a custom script. The images are pre-processed and fed into the Discriminator Network as the "existent" images. A prepare of 512 random numbers are chosen and fed into the Style Mapper and Generator Networks to create the "fake" images. Both the existent and faux images are modified with Adaptive Discriminator Augmentation, the key innovation in SG2A. I'll discuss this further down in the article. The chore of the Discriminator Network is to determine if the input is real or fake. The result is fed back into the 3 networks to train them. When the training is done, I post-process the output of the Generator Network to become the last images.
I'll go through each step in more detail in the sections below.
Gathering the Source Images
I use a Python script to gather images from WikiArt.org that are labeled as being "abstruse" and are in the public domain, i.e. created earlier 1925. The images are from the likes of Mondrian, Kandinsky, Klee, etc. The source code to gather the images is here. Here is a sample of the source paintings.

Pre-processing the Source Images
Here are the steps I use for pre-processing the images:
- Remove the frames: A Python script looks for and removes wooden (or other) frames effectually the images. The code is here.
- Resize to 1024x1024: GANs work best with foursquare images that are resized to exist a power of ii, eastward.m. 2¹⁰ = 1024
Here is a sample of pre-processed images.

Adaptive Discriminator Augmentation
One of the major improvements in SG2A is dynamically changing the amount of image augmentation during training.
Image augmentation has been around for a while. The concept is fairly unproblematic. If you don't have enough images to train a GAN, information technology tin lead to poor performance, similar overfitting, underfitting, or the dreaded "model collapse", where the generator repeats the same output image. A remedy for these problems is image augmentation, where you can utilize transformations similar rotation, scaling, translation, colour adjustments, etc., to create additional images for the training set.
A downside to paradigm augmentation is that the transformations can "leak" into the generated images which may not be desirable. For example, if you are generating human faces, you could use 90° rotation to augment the grooming data, but yous may non want the generated faces to be rotated. Nvidia found that augmentations can be designed to be non-leaking on the condition that they are skipped with a non-cypher probability. Then if most of the images existence fed into the discriminator are non rotated for augmentation, the generator will learn to not create images that are rotated [1].
…the preparation implicitly undoes the corruptions and finds the correct distribution, every bit long equally the corruption process is represented by an invertible transformation of probability distributions over the data infinite. We call such augmentation operators not-leaking. — Tero Karras, et al.
The new version of StyleGAN has a feature called Adaptive Discriminator Augmentation (ADA) that performs non-leaking prototype augmentations during training. A new hyperparameter, p, in the range of 0 to 1, determines how much and how often augmentations are to exist applied to both the real images and the fake images during training.
Here is a sample of augmentations with different values for p.



You can see how the sample images evidence more variety with spatial and color changes as p increases from 0.0 to 1.0. (Note that SG2A does not evidence the augmentation done to the real images during training. So I added the functionality to do this in my fork of the lawmaking, here. You lot can run a test in the Google Colab, hither.)
The value p starts at 0 when preparation begins, then increases or decreases if the system senses that there is overfitting or underfitting during grooming.
The heuristic used in the organization is based on the sign (positive or negative) of the output of the discriminator during the processing of a batch of generated images. If in that location are more than positive output values than negative, then the tendency is towards real images, which is an indication of overfitting. If there are more negative values than positive and then the tendency is towards faux images, which is an indication of underfitting. The value p is adjusted up or downwardly accordingly after the batch — upwards for overfitting and down for underfitting.
A target value for p can be set, i.due east. 0.7, and then there is e'er a non-zero probability that the augmentations can be skipped, which avoids leaking.
Yous tin read more about Adaptive Discriminator Augmentation in Mayank Agarwal'south mail here.
Training the System
I trained the organisation using Google Colab. It took almost four days to run. The organisation has an Nvidia Tesla V100 GPU which can run up to xiv teraFLOPS (14 trillion floating-point operations per second). Then information technology took about 4.6 exaFLOPS to train (virtually 4.6 quintillion floating-point operations). That's a lot of math.
Hither'due south the shell control I used to boot things off.
python stylegan2-ada/train.py --aug=ada --target=0.vii \
--mirror=1 --snap=1 --gpus=1 \
--data='/content/bulldoze/MyDrive/datasets/paintings' \
--outdir='/content/bulldoze/MyDrive/results_stylegan2_ada' Setting the aug parameter to ada enables the Adaptive Discriminator Augmentation to boot in when needed. Setting the target parameter to 0.7 prevents p from going over 0.seven, which maximizes the dynamic augmentation without leaking whatever farther augmentation into the final images.
Here's a graph of the training results over fourth dimension. I am using the Fréchet Inception Distance (FID) as a metric for paradigm quality and diverseness, where a lower score is better [2]. You tin read nigh the FID score in Cecelia Shao's post hither.
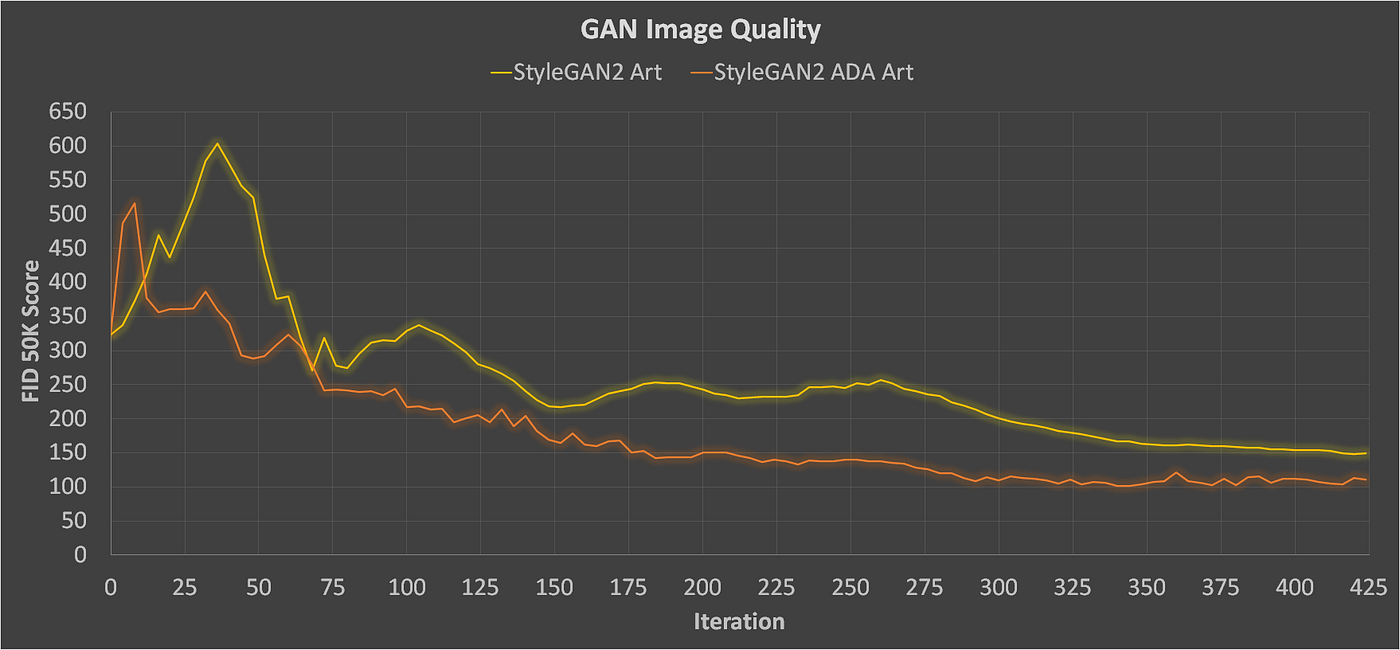
You can encounter how StyleGAN2 ADA outperforms the original StyleGAN2 for the same number of iterations. The FID score for SG2A bottomed out at just over 100 after about 300 iterations. Hither are some samples of the results.

The GAN seems to produce a nice variety of abstract paintings with interesting compositions with varied color schemes. But there is room for improvement.
Transfer Learning
It may non exist intuitive, but it's possible to improve the quality of the paintings by first training the GAN on a different, larger set up of images, and so further railroad train the model using the abstruse paintings. This technique is chosen Transfer Learning. It was first described every bit a technique for training NNs in 1976 [3].
Transfer Learning is technique that uses a pre-trained neural network trained for Task 1 for achieving shorter preparation fourth dimension in learning Chore 2. [4] — Stevo Bozinovski
From Landscapes to Abstract Paintings
I remember learning in my Art History 101 class that many abstruse painters started by painting figurative subjects, like people and landscapes. For example here are sequences of paintings by Mondrian, Klee, and Kandinsky that show their progressions from landscape to abstract art.









Learning from Landscapes
I wanted to see if I could transfer the learning from creating mural photos to perhaps improve its ability to create abstruse paintings.
As an experiment, I trained SG2A on 4,800 photographs of mural photos from Flickr that are in the public domain. The dataset, by Arnaud Rougetet, is available on Kaggle, here.
Hither is a sample of the photos from Flickr. Note that I resized the photos to be 1,024 ten 1,024 pixels each.

I trained the SG2A system using another Google Colab to create new mural images. It as well took most iv days to run the training. Here's the shell control I used.
python stylegan2-ada/train.py --aug=ada --target=0.7 \
--mirror=one --snap=1 --gpus=1 \
--data='/content/drive/MyDrive/datasets/landscapes' \
--outdir='/content/bulldoze/MyDrive/results_stylegan2_ada_landscapes' The command is nearly the same as the one I used to railroad train using the abstract paintings. The only differences are the paths to the landscape folders on Google Drive. Here's a graph that shows the FID scores of the grooming of landscapes (the greenish line).

The score for the generated landscapes is much improve than the abstruse paintings. Y'all tin see that it bottomed out effectually 25 afterward about 150 iterations. The reason the landscapes have a better score than the abstruse paintings is probably due to the larger training gear up — 4,800 landscapes and only 850 abstruse paintings.
Simulated Landscapes
Here are some generated mural photos that were created after iv days of training SG2A.

These look pretty adept. The horizons are a chip distorted and the clouds seem somewhat fantastical, merely they could otherwise pass as real landscape photos. Now allow'due south see if this learning can aid with creating abstract fine art.
Transferring the Learning
The next step of the experiment was retraining SG2A to create abstruse fine art starting with the model previously trained on landscapes. Here's a flow diagram that shows the procedure.
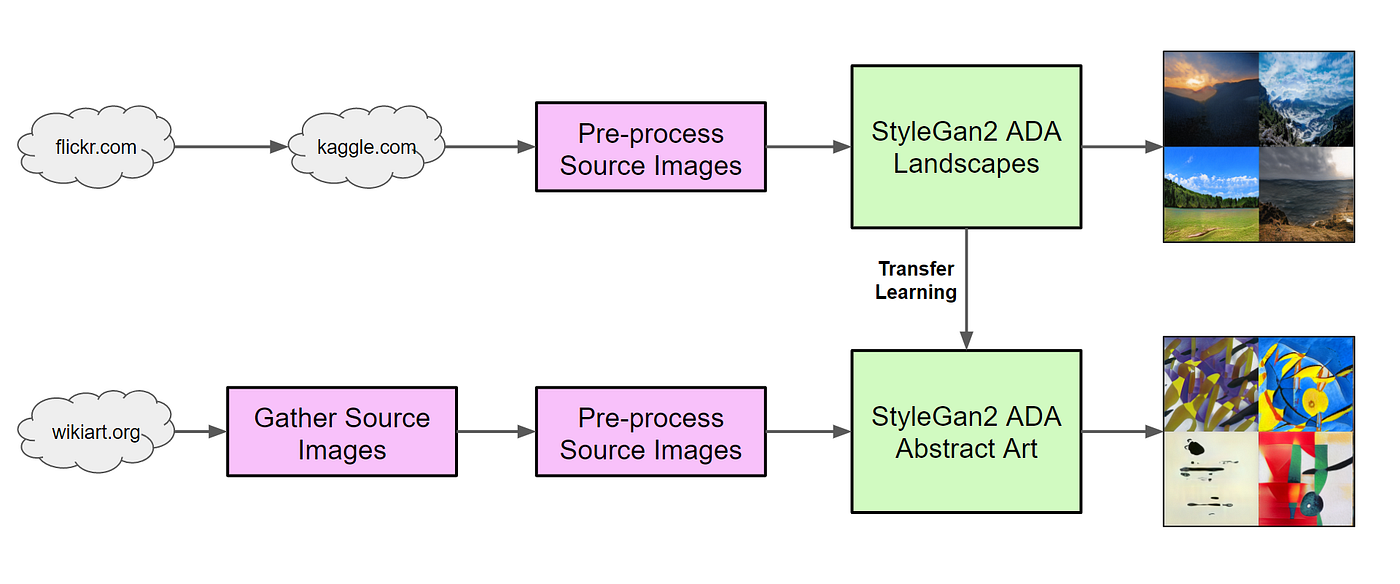
Subsequently the GAN was trained to create landscapes, it was farther trained to create abstract paintings using prior knowledge of the landscapes. I trained the organisation using a third Google Colab. Here's the shell command I used.
python stylegan2-ada/railroad train.py --aug=ada --target=0.seven \
--mirror=i --snap=1 --gpus=one \
--information='/content/drive/MyDrive/datasets/paintings' \
--resume='/content/drive/MyDrive/results_stylegan2_ada/00006-landscapes-mirror-auto1-ada-target0.7-resumecustom/network-snapshot-000048.pkl' \
--outdir='/content/drive/MyDrive/results_stylegan2_ada_tl'
I am grooming using abstract paintings, just the resume option starts the grooming with the GAN trained with landscapes. It took near iv days to run the final grooming. Here is a graph of the FID scores. The new results are in blue.

Y'all can see that Transfer Learning helped improve the scores. The FID numbers for the latest grooming run settle in effectually 85, which is better than the previous run with a score of about 105. Here are some sample images that benefitted from the Transfer Learning.

Information technology may be subtle, but the images created with the model with Transfer Learning announced to be more refined, pleasing compositions. Please cheque out the appendix below for a gallery of samples.
Generating Images
One time the GAN is trained, images can be generated using this command line.
python stylegan2-ada/generate.py --seeds=1-iv --trunc=i.v \
--outdir results --network=network-snapshot-000188.pkl This will generate iv images using random seeds 1, 2, iii, and 4. The truncation parameter, trunc, will make up one's mind how much variation there will be in the images. I found that the default of 0.5 is likewise depression, and 1.5 gives much more than diverseness.
Create your Own Painting
A Google Colab for generating images with a multifariousness of attribute ratios is bachelor hither. It generates 21 images and lets y'all choose one to see at high resolution. Here is a sample of images.

Adjacent Steps
Additional work might include grooming on paintings of landscapes instead of photos for the Transfer Learning. This may aid the GAN pick up on a painterly wait to use to abstruse paintings.
Acknowledgments
I would similar to thank Jennifer Lim, Oliver Strimpel, Mahsa Mesgaran, and Vahid Khorasani for their help and feedback on this project.
Source Code
The 850 abstract paintings I collected can be plant on Kaggle here. All source lawmaking for this project is available on GitHub. The sources are released under the CC BY-NC-SA license.

References
[1] Karras, T., Aittala, One thousand., Hellsten, J., Laine, South., Lehtinen, J., and Aila., T., "Grooming Generative Adversarial Networks with Limited Data.", Oct vii, 2020, https://arxiv.org/pdf/2006.06676.pdf
[2] Eiter, T. and Mannila, H., "Computing the Discrete Fréchet Altitude", Christian Doppler Labor für Expertensyteme, April 25, 1994, http://www.kr.tuwien.air-conditioning.at/staff/eiter/et-archive/cdtr9464.pdf
[three] Bozinovskim Due south., and Fulgosi, A., "The influence of pattern similarity and transfer learning upon training of a base perceptron B2." Proceedings of Symposium Informatica, 3–121–v, 1976
[4] Bozinovski, Due south., "Reminder of the commencement newspaper on transfer learning in neural networks, 1976". Informatica 44: 291–302, 2020, http://www.informatica.si/index.php/informatica/article/view/2828
Appendix A — Gallery of MachineRay 2 Results







hendersonthrusled.blogspot.com
Source: https://towardsdatascience.com/creating-abstract-art-with-stylegan2-ada-ea3676396ffb
0 Response to "Abstract Art Images Non Commercial Abstract City Art Images Non Commercial"
Post a Comment